bayesian p 与 hypothesis testing
Created: June 11, 2023 9:26 AM Last edited by: Pan Wanke Last edited time: June 11, 2023 9:26 AM Owner: Pan Wanke
- 问题:
在plot_posterior_nodes 和比较posterior probability的时候,这个PP值是越趋近0 好还是越趋近1好?我plot了5个条件下的posterior of v (如图),然后相邻两个进行了比较(print(“P(1>2)=”, (v_1.trace()>v_2.trace()).mean())),值都是接近1的。图看起来分布重合度很低,怎么理解这个结果?
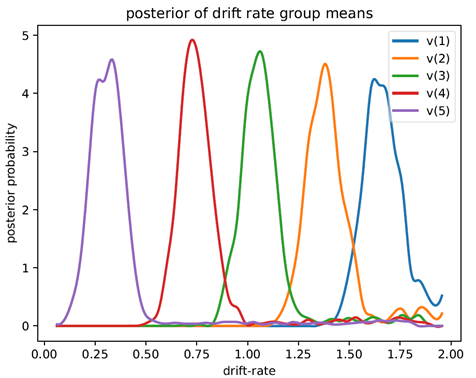
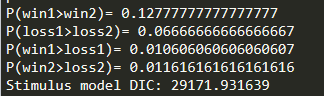
- 回答
这是贝叶斯的credible interval(可信区间或信任区间,类似于传统统计学的置信区间),95%区间不包含0就可以认为差异显著,跟传统统计学类似
这就是四不像。这就是贝叶斯方法向传统统计学妥协得到的产物。真正的贝叶斯方法基本都是基于模型比较的吧。
在HDDM中算BF最简单的方法就是用likelihood ratio,但这种做法也具有争议,加上比上面那个P值要复杂,所以用的人也不多
也可以用region of practical equivalence (ROPE) + highest density interval (HDI)(https://doi.org/10.1177/2515245918771304)(但又引出一个问题,如何确定ROPE)
ROPE的思路主观性太强了,我感觉也不好达成统一意见
关于双尾单尾检验问题,Michael Frank在HDDM群里的回复
首先,与经典统计学相比,贝叶斯检验更加关心我们可以以多大的置信度说出有关当前数据的结论,因此会报告参数及其差异的完整后验分布。
其次,虽然通常会使用类似于经典统计学中的阈值(例如后验分布的重叠度小于5%表示不同),但这并不等同于一或双尾检验。经典统计学的检验方法是问:如果没有参数间差异,我们进行多次实验是否有可能观察到与我们所观察到的值一样极端或更极端的值。而双尾检验则允许我们说这种极端观察值可能会出现在两侧。
贝叶斯统计学中常用的方法之一是最高密度区间(HDI),通常定义为95%的后验分布,分别在两侧为2.5%。因此,如果要使用HDI来比较两个参数之间的差异,则最多只能有2.5%的重叠,以使差异的HDI大于0。
但是,这些阈值是任意的,没有必要将后验分布的重叠度等同于p值,因此不需要将阈值改为0.025。在观察到后验分布差异时,还应进行参数恢复,以确定对估计参数值的置信度。
此外,还可以进行模拟研究,其中参数间存在接近于经验范围的基本真实差异,然后将模型拟合到这些模拟数据上,看看使用0.05或其他阈值在多大程度上能够恢复这些差异。原始的HDDM论文做了一些这样的研究,展示了检测真实效应的频率(并且使用分层推断可以提高这种频率),但也可以研究在没有差异时检测效应的频率。
最后,还可以在贝叶斯环境中绘制更复杂的校准图来进行进一步的分析。
DDM参数应该用传统的频率统计还是贝叶斯统计?
于宏波老师的一篇文章中,对ddm参数使用了贝叶斯统计,而不是传统的频率统计,看起来有人认为MCMC估计的参数在统计时也应该用贝叶斯统计方法;如果有审稿人问起,确实参考于宏波老师的应对方法
